




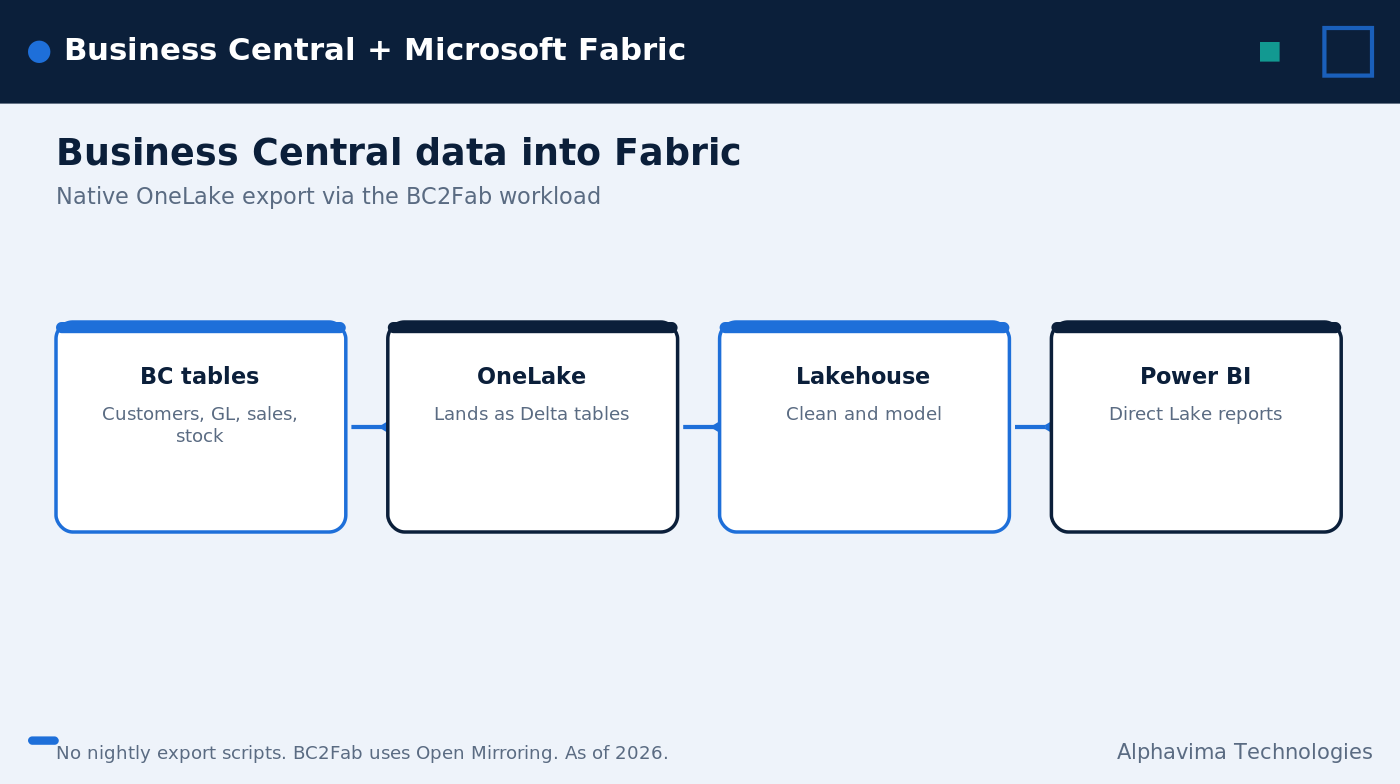
Business Central Microsoft Fabric integration gives you one governed copy of your ERP data for analytics, without writing nightly export scripts. The connection uses a native OneLake export that replicates Business Central tables into a Fabric Lakehouse, so the core setup needs no custom middleware.
In short, your ERP records move into OneLake, Fabric tools shape that data, and Power BI reads it back fast. This guide walks through the prerequisites, the numbered setup steps, and the considerations that keep the pipeline stable. Throughout, the goal stays practical: get clean Business Central data in Fabric and report on it with confidence.
The setup follows a clear path. First you confirm the basics, then you turn on the export, and finally you validate and report. None of the steps require code for the core flow, though a data engineer helps with the modeling later. Plan an afternoon for a first pass on a small set of tables, then expand from there. Here is the full sequence for the Business Central Microsoft Fabric integration.
- Confirm prerequisites. Check your Business Central environment, a Fabric capacity, a target workspace, and the right permissions before you begin.
- Create or pick the target. Choose the Fabric workspace and Lakehouse where Business Central data in Fabric will land.
- Turn on the integration. In Business Central administration, turn on the BC–Fabric/OneLake integration so the export can write to your Lakehouse.
- Select and map tables. Pick the Business Central tables you want to replicate, then map them to the Lakehouse destination.
- Choose refresh type and schedule. Decide between incremental and full refresh, then set a schedule that fits your reporting needs.
- Validate the data. Open the Lakehouse and confirm the Delta tables loaded correctly with the rows and columns you expect.
- Build a Power BI model. Create a Power BI Direct Lake model on the gold data and publish your reports.
- Monitor refreshes and schema changes. Watch refresh runs and keep an eye on Business Central schema updates so nothing breaks downstream.
As an alternative to step 3, you can use Dataflow Gen2 to pick tables into OneLake. That path suits teams that already build dataflows and want extra shaping before the data lands. Either way, the destination stays the same Lakehouse, so your downstream models do not care which method moved the data.
A note on order: do not skip the validation in step 6. It is tempting to jump straight to Power BI, yet a quick row count and a spot check on a few key tables catch mapping mistakes early. Fixing them before reports are built saves far more time than fixing them after stakeholders have seen the numbers.
Prerequisites checklist
Before you start, line up the items below. Missing any one of them usually stalls the setup, so verify each first.
